Ungoverned Context Is a Real Supply Chain Risk for Agentic Workflows
Ungoverned context is a real supply chain risk for agentic workflows. Most teams can identify the agent's runtime but have no way to reconstruct what sources actually shaped the output.
Agentic workflows for software development are consuming more context from more sources than most teams realize, and almost none of it is governed. How an agent gathers and inherits context during a workflow is a significant and overlooked risk. Context poisoning can go undetected, particularly as larger context windows and better tooling make ingestion easier. But poisoning is just the adversarial version of a more general problem: context the agent cannot verify. Whether the source was tampered with or simply went stale, the agent proceeds on a version of reality that does not match the one it is operating in.
A trend I have long advocated is for platform engineering teams to own Agentic workflows the same way they own CI/CD pipelines today. These teams already build and maintain automation, integrate tools, standardize processes, and reduce complexity for developers. Extending this model to AI, platform teams can connect relevant data sources and create reusable workflows for development teams. These 'golden pathways' are governed, opinionated, and ready to use. That model makes sense. The gap is that most organizations still do not govern what an agent is allowed to treat as authoritative context. Each integrated data source expands the context supply chain, and with it the risk of prompt injection, stale guidance, and hidden upstream transformation.
This challenge is particularly difficult to address because:
- Most companies do not have clear ownership over what an agent is allowed to treat as authoritative.
- Prompt and response logging are still immature, but even where auditability exists, it often stops at the final payload. Earlier processing steps can still obscure risk. OWASP refers to this as indirect prompt injection, but the practical attack surface is likely much broader than most teams assume.
- Context provenance is often incomplete, which makes it hard to determine where information actually came from once it has passed through several processing steps.
- Context is often assembled from multiple sources, but treated as one coherent input, which hides the lineage of each source.
Why Context Cannot Be Trusted by Default
Consider a simple SDLC workflow: an agent is created to validate a merge request review against a ticket for a bug in an external system. The agent is configured to access the ticket's content.
The ticket or a linked artifact, such as a runbook, could contain poisoned content. This can enter the workflow in several ways, listed here in roughly increasing detection difficulty:
Even with prompt and context auditing, the system cannot validate information it is unaware of. A workflow may log the final context payload and still miss the hidden retrieval, ranking, enrichment, or summarization steps that shaped it. Validity checks may incorrectly assume the returned context is the sole source of truth, even when upstream context is ungoverned.
This lack of ownership is frequently overlooked and extends beyond technical vulnerabilities, such as prompt attacks and compromised documentation. A common example is open-source projects used as libraries. A traditional supply-chain attack involves code tampering, which can be mitigated through security processes such as pinning to a specific SHA or using curated services. But if documentation contains a prompt injection and an AI agent uses it for context, those mitigations do not apply. Even if you trust the documentation source, harder-to-detect variations exist, such as prompt injections embedded in stale or outdated documentation that an agent still retrieves as relevant.
This is a critical gap because most teams can identify the agent's runtime, but few can specify the authoritative sources the agent relied on.
The False Sense of Confidence
In more mature software organizations, I have observed the implementation of audit gates to establish a clear record of what the agent consumed.
These organizations request the specific version of the internal API specification, the prompt, the model, and the tools used to gather context (such as agent.md files or MCP tools).
This looks thorough on the surface. However, when examining context gathering, they can usually specify only the retrieval method. They cannot provide the exact documentation used or identify the upstream processing steps that may have affected the payload.
Currently, Agentic workflow provenance is often treated like a traditional BOM, which collects metadata about the build process. However, agentic workflows are not linear and require a different approach.
- Why this dependency? Was it selected based on relevance determined by the context retrieval logic or specified in the prompt criteria?
- Where did this implementation pattern come from? Did it come from an approved source or from exploratory retrieval?
- What standard is this following? Was it based on the current standard or a stale internal document?
- Was this based on the current API contract or an outdated internal doc? Is there a way to track this level of detail?
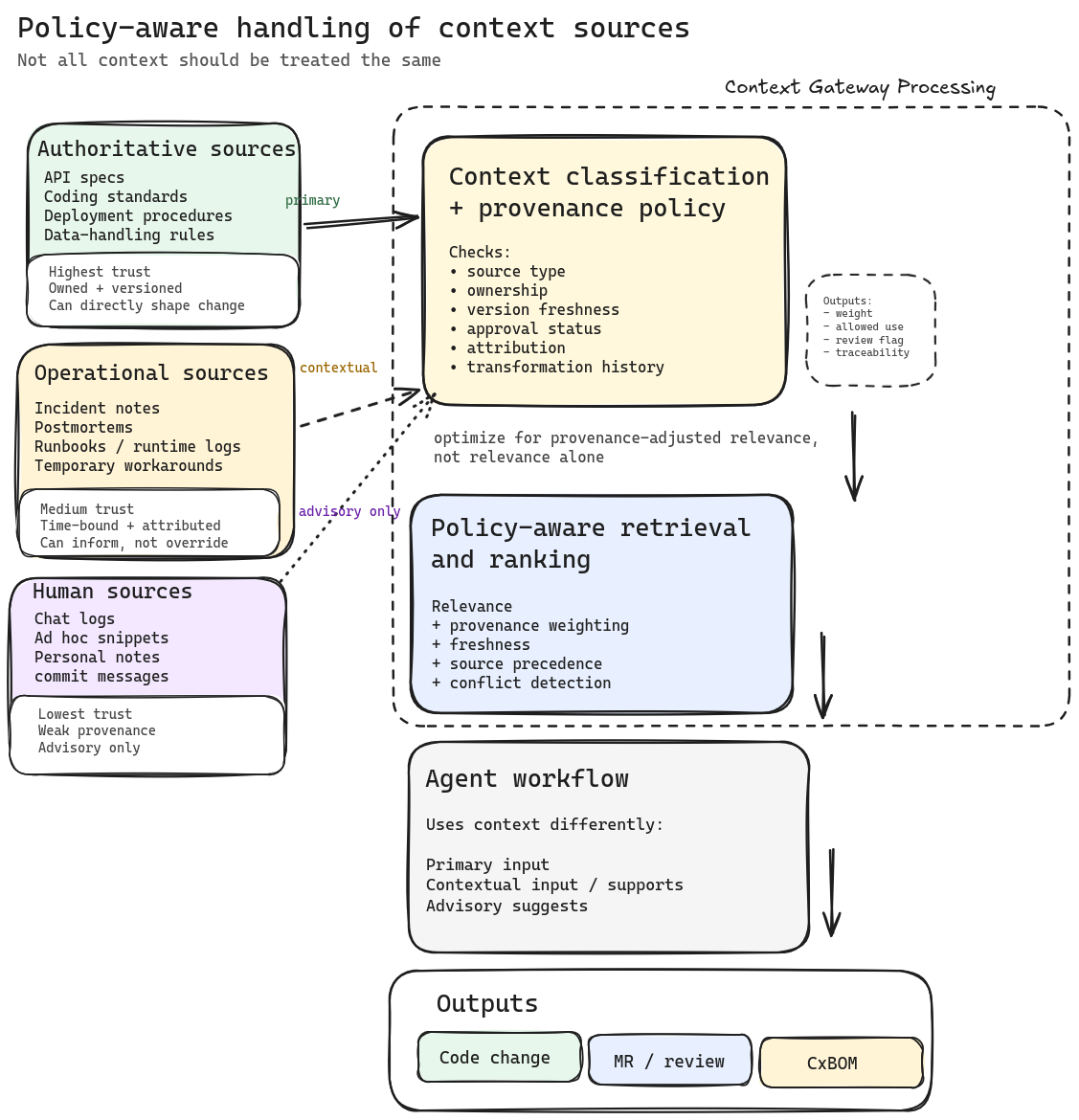
Not All Context Should Be Treated the Same
Most organizations have not explicitly distinguished between the types of context an agent can access, which makes it difficult to reduce risk.
You can have reasonably controlled and well-defined sources, such as API specifications, secure coding standards, deployment procedures, and data-handling rules, where ownership, versioning, and change control should be expected.
Then you have contextual operational sources, such as incident notes, postmortems, and temporary workarounds. These are probably fine, but they at least need to be time-bound and require attribution.
Last, you have the "human sources" that fill in the gaps, such as chat logs, ad hoc snippets, and personal notes. These may assist humans, but should not serve as authoritative inputs for production-impacting code.
The problem is that these agent retrieval systems blur all of this together. They surface what scores highest for relevance, not what has the strongest provenance.
As a result, a stale wiki page may outrank a reviewed API specification, and a workaround from an incident thread can inadvertently become policy. This is how non-malicious poisoned context can be accepted as truth.
Authoritative sources are condition-defining: they describe what is currently true about how the system should behave. The problem with classifying sources as trusted or untrusted is that classification is a snapshot. An API specification is authoritative until the contract changes. Whether the retrieved version still reflects how services actually communicate is a question about current state, not source provenance. An agent reading a superseded specification will make reasonable-looking decisions based on a version of the system that no longer exists, and a trust classification gives no signal that anything is wrong.
One idea that comes to mind is to have a way to flag sources as "trusted" or "untrusted" and to have a way to track the provenance of the context, then use a gateway to rank, filter, and produce a curated context payload based on that before the context is provided to the agent.
This gateway could also be used to enforce policies around context usage, such as requiring human review for certain types of context or limiting the amount of context that can be provided to an agent. The idea here is that the gateway would be the single source of truth for what context is provided to the agent and be able to run across multiple agent instances to ensure consistency and allow for centralized policy enforcement.
The Wrong Fix Is Trying to Bless Everything
Some teams attempt to address this by creating a registry of approved knowledge sources with designated owners, versions, and mandatory traceability.
The intention is correct, but execution often falls short.
Attempting to govern every document, note, and operational detail creates a parallel documentation system that is difficult to maintain. Teams may stop updating it, guidance shifts back to tickets and chat threads, and the registry becomes outdated, creating a false sense of accuracy.
It is unnecessary to approve every piece of context. Instead, establish a contract specifying which sources may influence production-impacting changes in higher-risk workflows. Set flags for uncertainty to help human reviewers focus on critical tasks.
Building a Context Bill of Materials (CxBOM)
For designated repositories, treat context as a supply chain input.
If an agent-assisted change affects payments, identity, customer data, pricing, access control, or other sensitive areas, the merge request should include sufficient information to reconstruct the context behind the change.
This process does not need to be complex; a minimal Context Bill of Materials is sufficient. Most of this information can be captured from the agent's execution logs and metadata. The key is tying the context back to the specific pipeline and the change set in the merge request.

- Which system did the context come from?
- Who owns it?
- What version was retrieved?
- What type of source was it: authoritative, operational, or ambient?
- Which pipeline run ties back to the change?
- What conditions were active at the time? Open incidents against relevant services, pending breaking changes in dependencies, or recent policy revisions that had not yet propagated to authoritative sources are part of the state the agent was operating in.
This is the minimum required to address questions during reviews, audits, and incidents. Without this, teams are forced to make assumptions after the fact.
Furthermore, it gives reviewers enough lineage to decide whether the change should be trusted in the first place.
This is also where the source record and the condition record diverge. Source provenance tells you what the agent was given. The question an incident review or compliance examination will actually ask is why the agent behaved as it did given what it knew. An agent that approved a change because the relevant policy document looked current, while two open incidents involving the same service had been logged in the previous week, made a traceable error. Source provenance alone cannot surface that. A record of which conditions were active at the time of the decision is what turns a context log into a reconstruction.
Note: This discussion focuses on context consumption specifically. Code produced by the agent should also be traceable to the model, tools, and prompt that generated it, but that is a separate topic. If you want to go deeper on that side of it, I'd suggest reading This article about code provenance by Lee Faus.
This Is Also Why Tool Evaluations Never Really End
When the context layer is unmanaged, tool evaluations become a matter of trust.
Evaluations must consider retrieval behavior, source handling, and provenance in addition to model quality. This often leads organizations to repeat evaluations without gaining confidence.
The trust boundary remains unstable because the context layer is still unmanaged.
A shared context contract stabilizes the trust boundary, allowing tool changes to become configuration decisions rather than requiring full re-validation.
Where I Would Start
Before building anything, audit what your agents are actually consuming. For each agentic workflow, map every source that feeds context into the agent: retrieval endpoints, knowledge bases, linked artifacts, tool outputs, and any upstream enrichment or summarization steps. For each source, document who owns it, whether it is versioned, how frequently it changes, and whether the agent can distinguish a current version from a stale one. Most teams that do this for the first time find sources in the chain they did not know existed.
That audit gives you the inventory. The next step is classification. Apply the authoritative, operational, and ambient distinction from earlier in this article to each source and assign ownership. Authoritative sources get versioning and change-control requirements. Operational sources get time-bound validity. Ambient sources get flagged so reviewers know they are present but unverified. This classification becomes the contract that the workflow operates under.
With that contract in place, the next evolution is a context bus: a processing layer that sits between your sources and the agent, responsible for enforcing the contract at retrieval time. The bus handles source classification, provenance tagging, staleness detection, and policy enforcement before the context payload ever reaches the agent. It is also where you generate the CxBOM. Instead of relying on the agent's own execution logs to reconstruct what happened, the bus produces a structured record of what was retrieved, from where, at what version, and what policies were applied. This is the layer that makes context governance operational rather than aspirational, and it is where platform engineering teams should be investing once the audit and classification work is done.